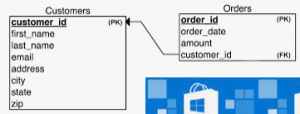
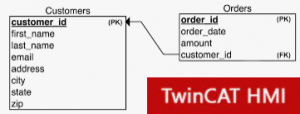
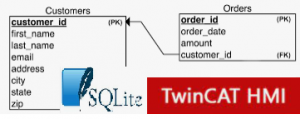
Databases play a crucial role in industrial automation, acting as the central nervous system of the system. They collect, store, and organize large volumes of data from sensors, machines, and control systems, enabling real-time monitoring, informed decision-making, and process optimization.
SQL databases are commonly used to manage data generated by automation systems. This data can be stored locally or in the cloud using different approaches, depending on system requirements. In our fictitious automation system, we will use a PostgreSQL server as the database solution.
In this tutorial, we will learn how to install an SQL server on a local machine or on other devices, such as a PLC. The tutorial is divided into two main parts:
Installing the MS SQL Server
Using the SQL server within an automation project in the TwinCAT HIMI environment
To fully understand how databases integrate with automation systems, we will also explore basic data modeling concepts through sample applications.